↤ December 19th, 2013
Heya Stranger! You probably came here to better understand CouchDB conflicts, and this post will help you to do so.
Should you need any more help with CouchDB, my company, Neighbourhoodie Software is offering world-class CouchDB support. Get in touch, now. :)
As part of a summary what Nodejitsu is planning to do with the scalenpm.org campaign money, they said:
All of these problems stem from the same symptom: conflicts in CouchDB. If you’re new to CouchDB you can read up on conflicts here. Conflicts are caused in the npm registry because (depending on several factors) a given publish can involve multiple writes to the same document. When these writes do not hit the same CouchDB server conflicts are generated. There are other medium-term solutions to scaling writes (such as sticky HTTP sessions), but conflicts will inevitably arise so we must address the symptom as well as the cause.
Of course CouchDB has a concept of conflicts, they are core to what makes CouchDB great: master-less peer to peer replication of your data. But I feel they are misrepresented here, so I’ll try and clarify things a little.
We will find out that the symptom isn’t CouchDB’s conflicts feature, but how the npm client treats CouchDB document updates in a way that is not recommended (note that I’m not trying to point any fingers here, I just hope people can learn from this :).
The standard way to store data in CouchDB is to HTTP PUT a JSON object into a CouchDB database:
PUT /database/document
{"a":1}
When retrieving that document, it it will look like this:
GET /database/document
{"_id":"document","_rev":"1-23202479633c2b380f79507a776743d5","a":1}
CouchDB will automatically add two properties to our JSON object, an _id and a _rev. The _id represents whatever we named the document in the initial request (we can also let CouchDB assign a random _id) and the _rev, or “revision” represents an opaque hash value over the contents of a document.
To change the value of a document, we need to prove to CouchDB that we know what its latest revision is:
PUT /database/document
{"_id":"document","_rev":"1-23202479633c2b380f79507a776743d5","a":1, "b":2}
The next time we get the document it looks like this:
GET /database/document
{"_id":"document","_rev":"2-c5242a69558bf0c24dda59b585d1a52b","a":1, "b":2}
You see the revision updated. Now lets try to update the document again, but provide the old _rev:
PUT /database/document
{"_id":"document","_rev":"1-23202479633c2b380f79507a776743d5","a":1, "b":2, "c":3}
We get:
{"error":"conflict","reason":"Document update conflict."}
This way, CouchDB ensures that a client never accidentally overwrites any data it didn’t know about. Think about this like a wiki editing system: one person edits a wiki page and adds a few paragraphs of new information while another person just fixes a typo halfway through the first person writing their contribution. Without any cleverness, the first person will overwrite the second’s person typo fix when they save their version (or revision) of the wiki page. To ensure they don’t, each revision could be tagged with a _rev that the client then need to provide when writing back to the server. If they don’t match, the client needs to re-read the document and merge any other changes that might have happened in the meantime (the typo fix) and then try to save the wiki page again. In more technical terms, this is called “optimistic locking”. This is to avoid the scenario of “pessimistic locking” where the second person has to wait for the first person to make their changes before they can edit the wiki page.
CouchDB works the same way and for good reasons, but it can be counter-intuitive to how people are used to working with databases. Some users think their way out of this without really understanding why CouchDB works this way. When they encounter a document update conflict, they will make a GET or HEAD request to CouchDB to learn about the latest _rev of a document and then use that for a second write request without first regarding the new data that has appeared on the server. In some cases, this is a viable strategy, especially, if only a single database server is involved and changes to documents are restricted to one or very few users (like in npm).
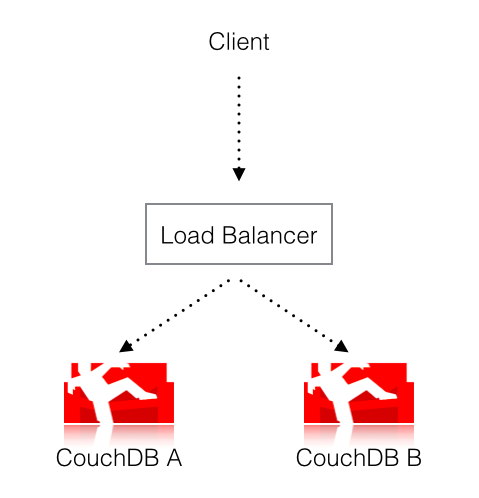
Now the fun part is when we add more database servers. One way to set up CouchDB is to run multiple instances behind an HTTP load balancer (because that’s really easy to do) and set up bi-directional replication between the two databases. This helps with reliability and load distribution, as two servers can share the read-load and if specced correctly, a single server can survive the outage of the peer, while the load balancer ensures that users never see a difference.
A load balancer usually distributes reads and writes randomly between the two CouchDBs. This is where the fun begins. Let us update our document once more:
PUT /database/document
{"_id":"document","_rev":"2-c5242a69558bf0c24dda59b585d1a52b","a":1, "b":2, "d":4}
Now this gets written to CouchDB A because the load balancer decides so. CouchDB A now has:
GET /database/document
{"_id":"document","_rev":"3-2235fd4815b81b2da1b84159aba4006e", "a":1, "b":2, "d":4}
But CouchDB B still has:
GET /database/document
{"_id":"document","_rev":"2-c5242a69558bf0c24dda59b585d1a52b","a":1, "b":2}
Usually replication updates this quickly, but it might take a while due to write load, and if the client sends multiple requests in quick succession, there is a fair chance that updating the document yet another time will hit CouchDB B which will reject the write, because the _rev doesn’t match any more:
PUT /database/document
{"_id":"document","_rev":"3-2235fd4815b81b2da1b84159aba4006e", "a":1, "b":2, "e":5}
Returns:
{"error":"conflict","reason":"Document update conflict."}
If we use the strategy of quickly getting the _rev from the doc and trying again, we might GET from CouchDB B again, to get "_rev": "2-c5242a69558bf0c24dda59b585d1a52b" and attempt the write again:
PUT /database/document
{"_id":"document","_rev":"3-c5242a69558bf0c24dda59b585d1a52b", "a":1, "b":2, "e":5}
If this PUT also goes to CouchDB B (you see this scenario is getting less and less likely, but it is still possible and certainly expected in a system like npm’s), this write will succeed and now we two conflicting revisions on CouchDB A and CouchDB B:
CouchDB A: 3-c5242a69558bf0c24dda59b585d1a52b
CouchDB B: 4-8b6ea819bf3384b2c215fd05fc5a1e5a
When CouchDB replication now runs, it will introduce a conflict on both CouchDB’s, as it is expected to. But since this is an undesirable situation, CouchDB generally recommends against using this strategy to deal with document update conflicts.
There are multiple ways to fix this:
GETs and POSTs. It is my understanding that the npm developers are working on that (Run npm install -g npm to make use of this without waiting for the next node release, thanks @izs)._rev locally in the client without also merging any new data from the server. I hope the npm developers are also taking this into account.I hope I could shed a bit of light on a thing that we, the CouchDB developers, have thought about a lot in the design of CouchDB, but have obviously failed to communicate sufficiently in the earlier days of CouchDB.
Let me close with saying the Team CouchDB is proud to support npm and the node community! <3